Расчленяем Многопоточность
#volatile #membar #dragons #openjdk
#jmm #store #load #internals
#cachecoherency #omg
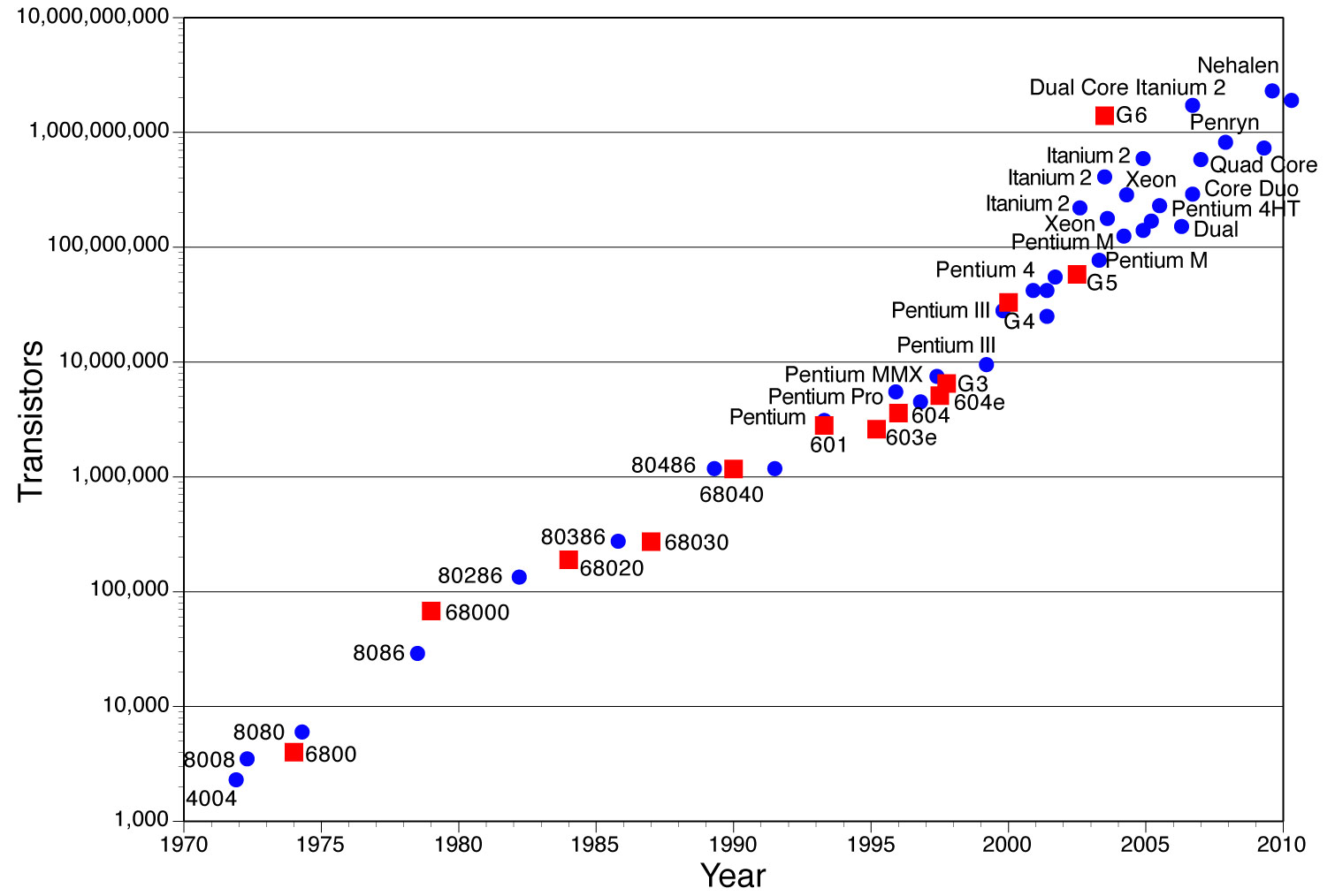
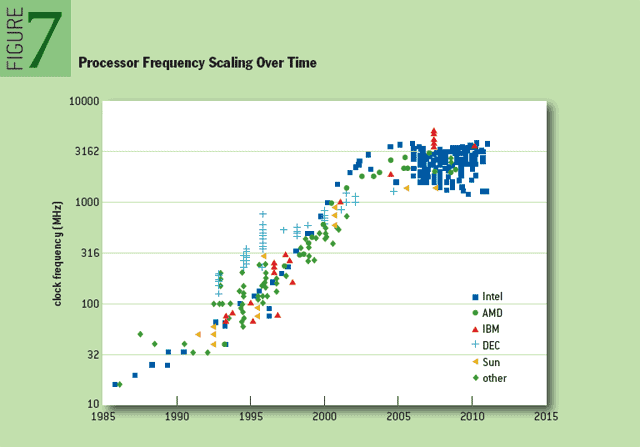
Результаты Теста (x86)
- f: 0, v: 3
- f: 0, v: 0
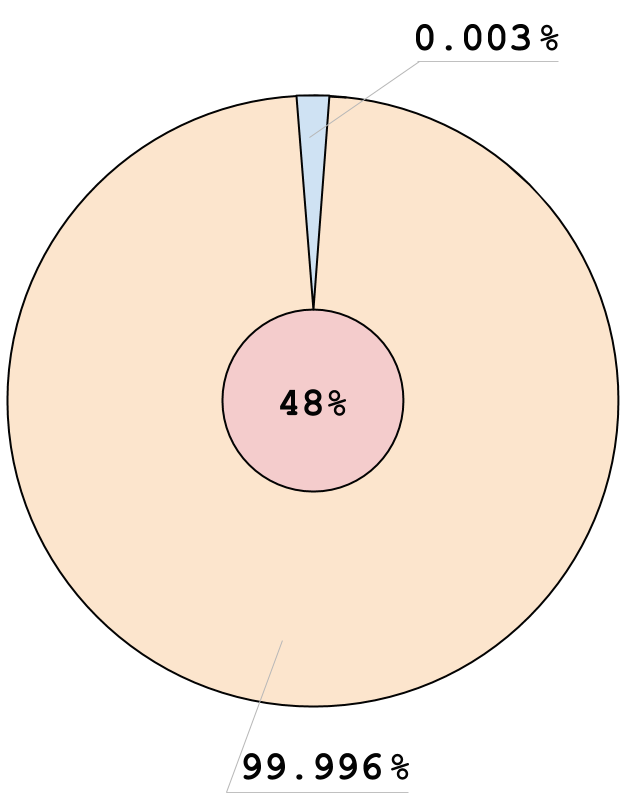
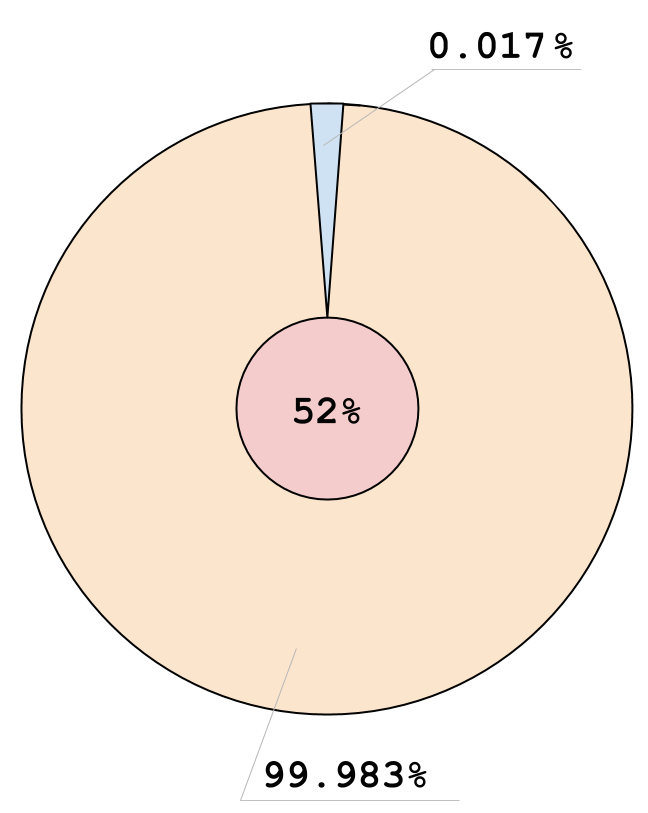
- f: 1, v: 0
- f: 1, v: 3
Результаты Теста (ARM)
- f: 0, v: 3
- f: 0, v: 0
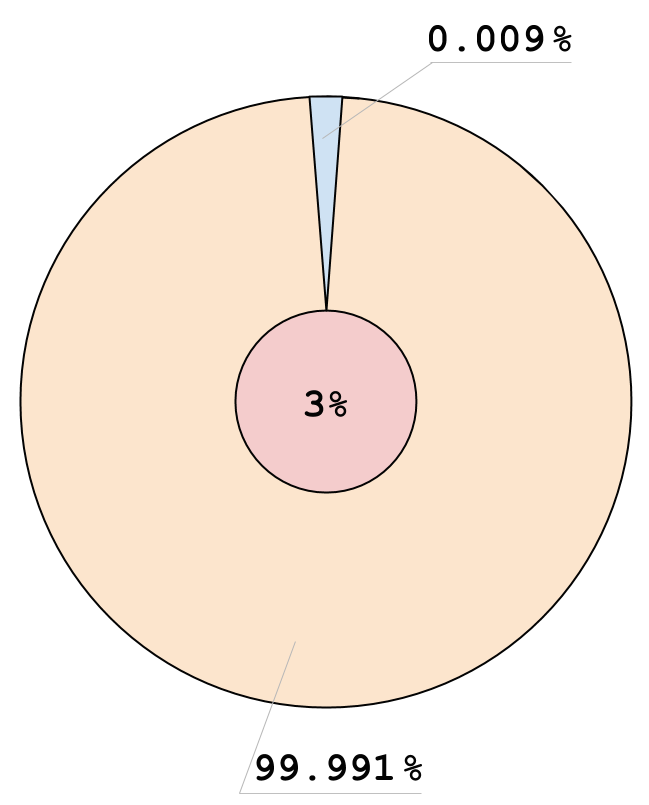
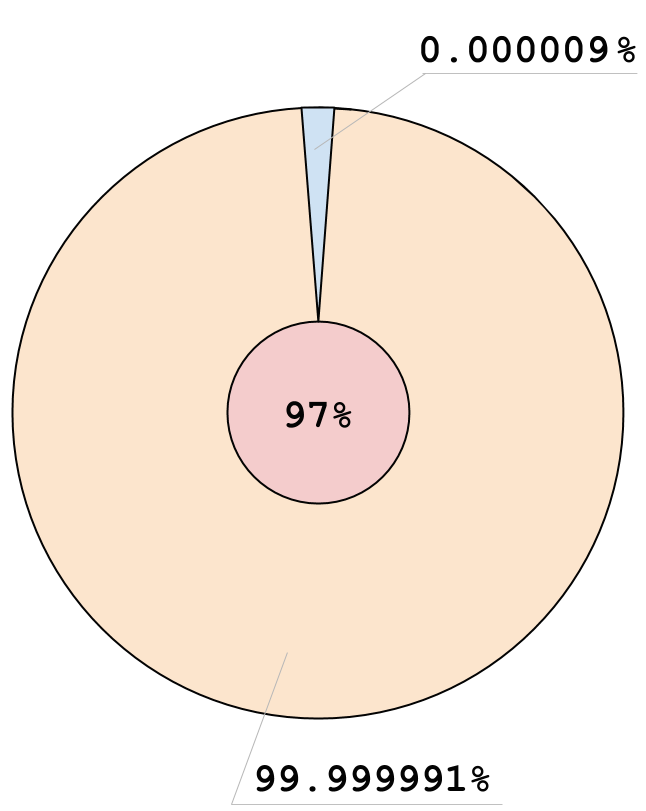
- f: 1, v: 0
- f: 1, v: 3
Результаты Теста (x86, C1)
- f: 0, v: 3
- f: 0, v: 0
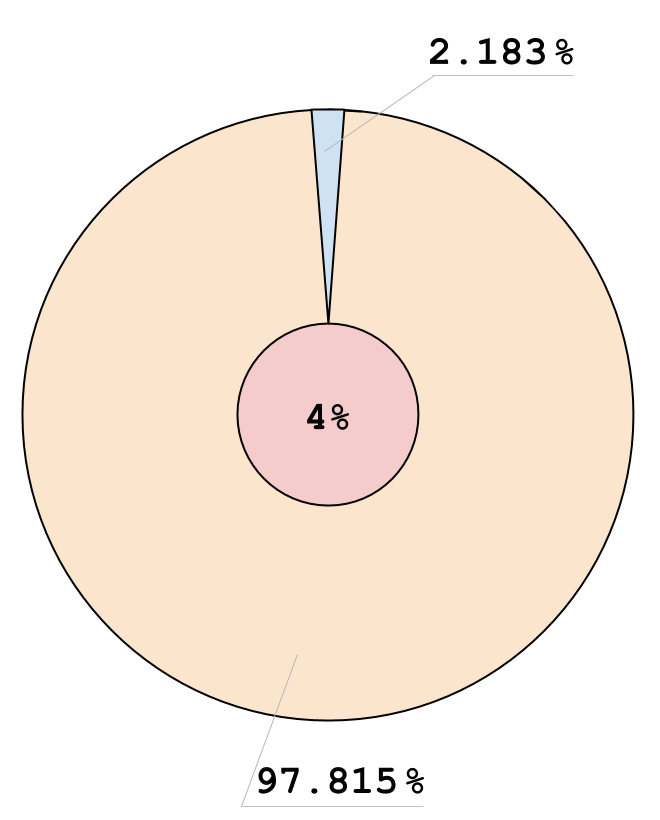
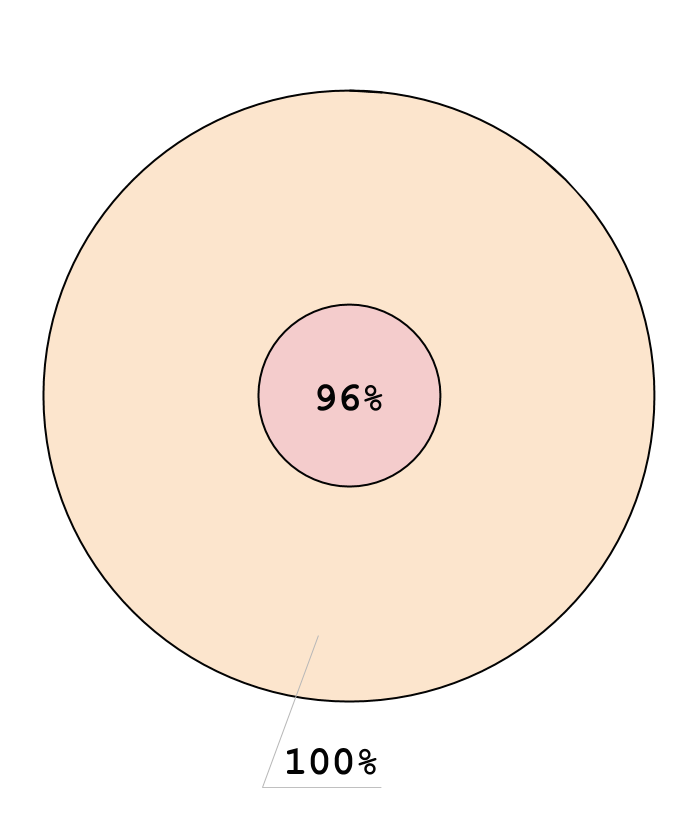
- f: 1, v: 0
- f: 1, v: 3

Куда Протекли Абстракции?
void executedOnCpu0() {
value = 10;
finished = true;
}
↓

↓

↓



| Variable | Cached Value |
|---|---|
finished |
false |
value |
N/A |
| Variable | Cached Value |
|---|---|
finished |
N/A |
value |
0 |
value ← 10;
- — Удали из кеша!
- ...
- ...
- — Я удалил!
finished ← true;
- Пришлось ждать очень долго
- Процессор простаивал
- Вы — самое слабое звено!
- Время оптимизировать
value ← 10;
→
(исполняется асинхронно)
finished ← true;
→
(тоже)

Memory ordering in some architectures
| Type | Alpha | ARMv7 | PA-RISC | POWER | SPARC RMO | SPARC PSO | SPARC TSO | x86 | x86 oostore | AMD64 | IA-64 | zSeries |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loads reordered after loads | Y | Y | Y | Y | Y | Y | Y | |||||
| Loads reordered after stores | Y | Y | Y | Y | Y | Y | Y | |||||
| Stores reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | ||||
| Stores reordered after loads | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| Atomic reordered with loads | Y | Y | Y | Y | Y | |||||||
| Atomic reordered with stores | Y | Y | Y | Y | Y | Y | ||||||
| Dependent loads reordered | Y | |||||||||||
| Incoherent instruction cache pipeline | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
(via https://en.wikipedia.org/wiki/Memory_ordering )

Так Делать Нельзя

Зато Можно Так

Write Once

Run Anywhere


Чувак, я ничего не понял из того, что ты сейчас сказал.
Но ты заговорил и достучался моего до сердца.
(исходник)
→
javac
(байт-код)
→
Frontend
(HIR)
→
JIT-Оптимизатор
(LIR)
→
Backend
(нативный код)
→
...
(???)
→
PROFIT!

LIVE DEMO TIME!
void executedOnCpu0 0: aload_0 1: bipush 10 3: putfield #2 6: aload_0 7: iconst_1 8: putfield #3 11: return
void executedOnCpu1 0: aload_0 1: getfield #3 4: ifne 10 7: goto 0 16: aload_0 17: getfield #2 // ...
void executedOnCpu0:
StoreField(value)
StoreField(finished)
void executedOnCpu1:
LoadField(finished)
LoadField(value)
void executedOnCpu0:
lir_move(value)
lir_membar_release
lir_move(finished)
lir_membar
void executedOnCpu1:
lir_move(finished)
lir_membar_acquire
lir_move(value)
# {method} 'executedOnCpu0' '()V'
...
0x00007f6d1d07405c: movl $0xa,0xc(%rsi)
0x00007f6d1d074063: movb $0x1,0x10(%rsi)
0x00007f6d1d074067: lock addl $0x0,(%rsp)
# {method} 'executedOnCpu1' '()V'
...
0x00007f6d1d061126: movzbl 0x10(%rbx),%r11d
0x00007f6d1d06112b: test %r11d,%r11d